Overview

“Figure 7: An example image-question pair from the VQS dataset and the corresponding execution trace of NS-CL.”
This work proposes the Neuro-Symbolic Concept Learner (NS-CL), a model that learns visual concepts, words, and semantic parsing of sentences without explicit supervision on any of them; instead, the model learns by simply looking at images and reading paired questions and answers. The proposed model builds an object-based scene representation and translates sentences into executable, symbolic programs. To bridge the learning of two modules, it uses a neuro-symbolic reasoning module that executes these programs on the latent scene representation.
Learning pattern of human
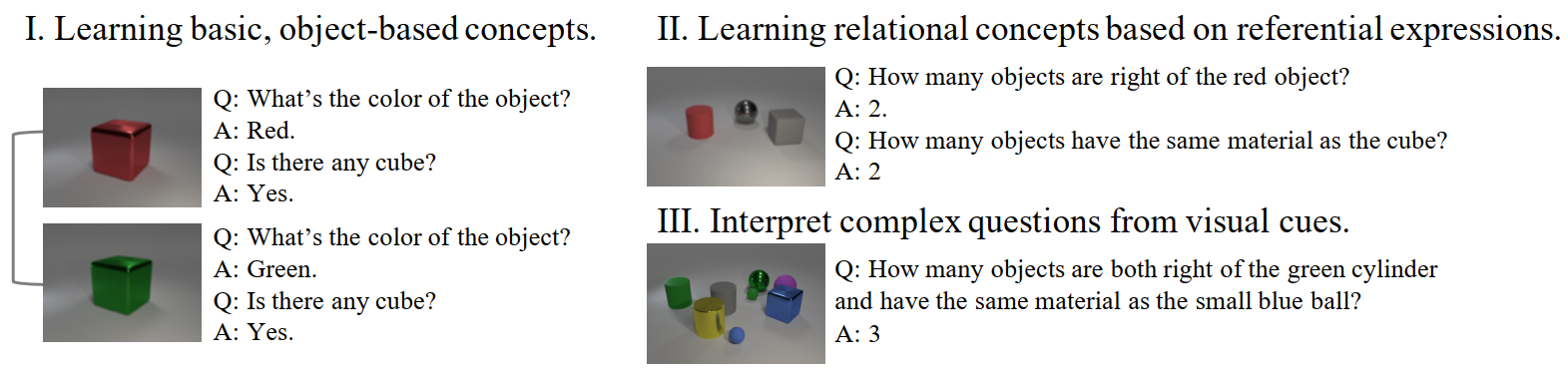
“Figure 1: Humans learn visual concepts, words, and semantic parsing jointly and incrementally. I. Learning visual concepts (red vs. green) starts from looking at simple scenes, reading simple questions, and reasoning over contrastive examples (Fazly et al., 2010). II. Afterwards, we can interpret referential expressions based on the learned object-based concepts, and learn relational concepts (e.g., on the right of, the same material as). III. Finally, we can interpret complex questions from visual cues by exploiting the compositional structure.”
Framework
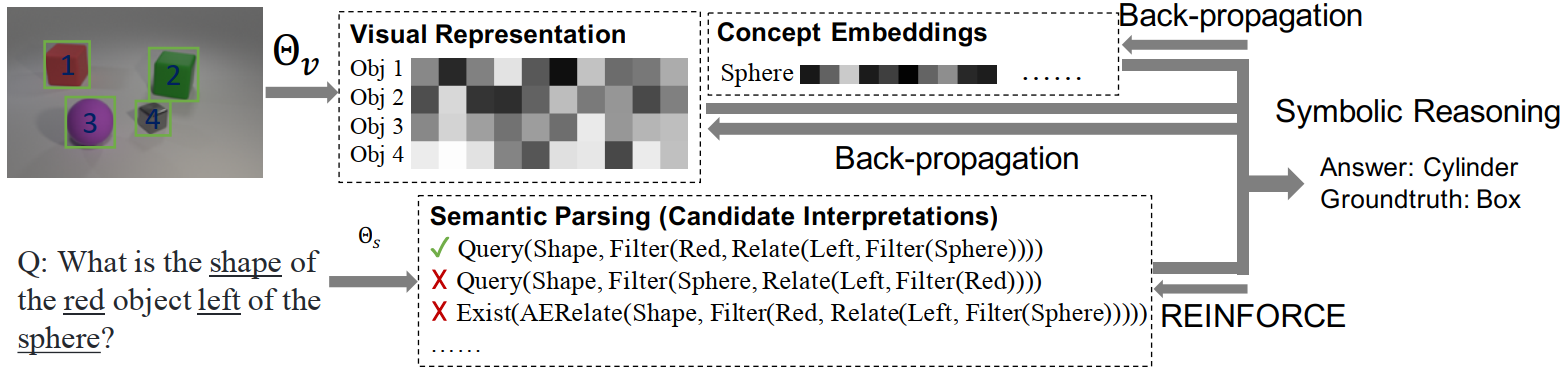
“Figure 2: We propose to use neural symbolic reasoning as a bridge to jointly learn visual concepts, words, and semantic parsing of sentences.”

“Figure 3: We treat attributes such as Shape and Color as neural operators. The operators map object representations into a visual-semantic space. We use similarity-based metric to classify objects.”
Curriculum concept learning

“Figure 4: A. Demonstration of the curriculum learning of visual concepts, words, and semantic parsing of sentences by watching images and reading paired questions and answers. Scenes and questions of different complexities are illustrated to the learner in an incremental manner. B. Illustration of our neuro-symbolic inference model for VQA. The perception module begins with parsing visual scenes into object-based deep representations, while the semantic parser parse sentences into executable programs. A symbolic execution process bridges two modules.”
Methods
The work first introduces the domain-specific language (DSL) designed for the CLEVR VQA dataset.
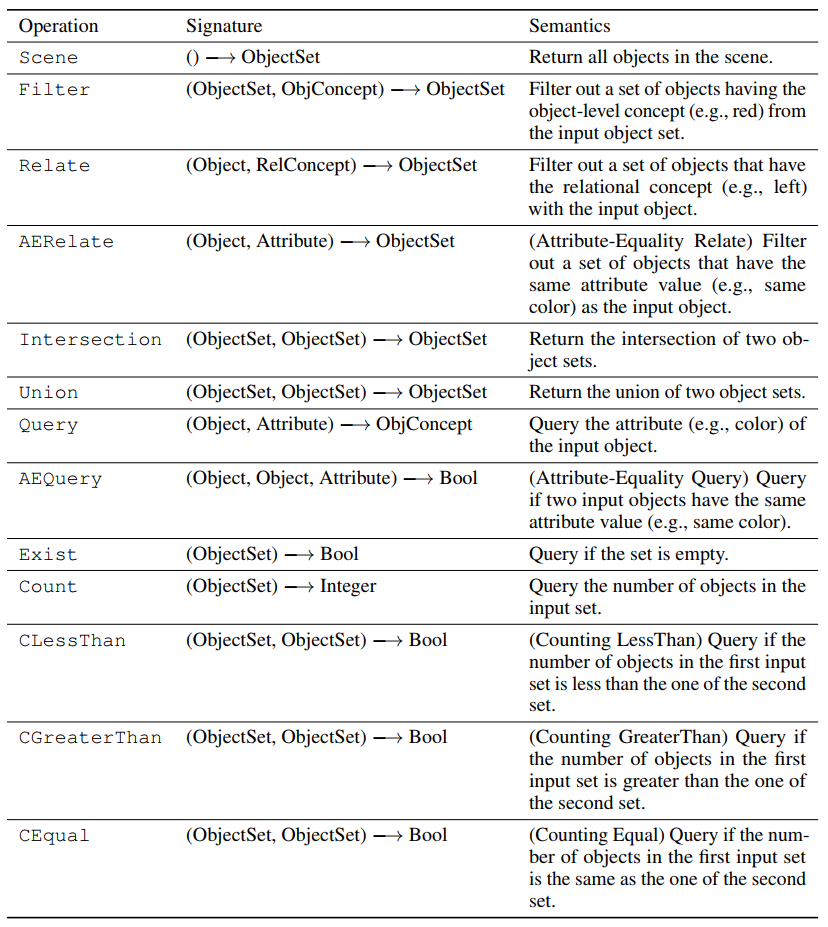
“Table 6: All operations in the domain-specific language for CLEVR VQA.”
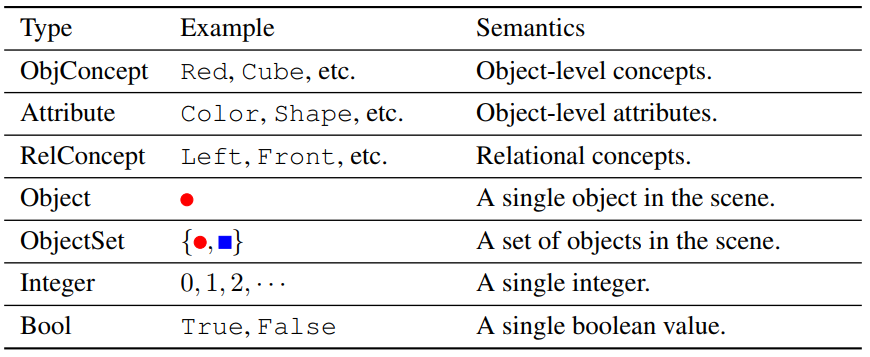
“Table 7: The type system of the domain-specific language for CLEVR VQA. "
Unfamiliar knowledge
Note: May include buzz word and potential literature.
Resources
Elementary drafts
Note: May contain Chinese. This section will disappear once all drafts are embellished.
collapsed contents
something一些草稿