Overview

“Figure 1: Statistics and examples from the synthetic CLEVR dataset and the real GQA dataset. Compared to the synthetic dataset, VQA on real data needs to deal with long-tail concept distribution and uneven importance of reasoning steps.”
Motivation
While neural symbolic methods demonstrate impressive performance in visual question answering on synthetic images, their performance suffers on real images. This work identifies that the long-tail distribution of visual concepts and unequal importance of reasoning steps in real data are the two key obstacles that limit the models’ real-world potentials.
Resolution
The paper proposes a new paradigm named Calibrating Concepts and Operations (CCO), which introduces an executor with learnable concept embedding magnitudes for handling distribution imbalance, and an operation calibrator for highlighting important operations and suppressing redundant ones.

“Figure 2: A failure case that can be corrected by reweighting the operations. The select(bag) operation overrides filter(not black), thus lead to incorrect answer. This can be corrected by scaling up the result of filter operation.”
Framework
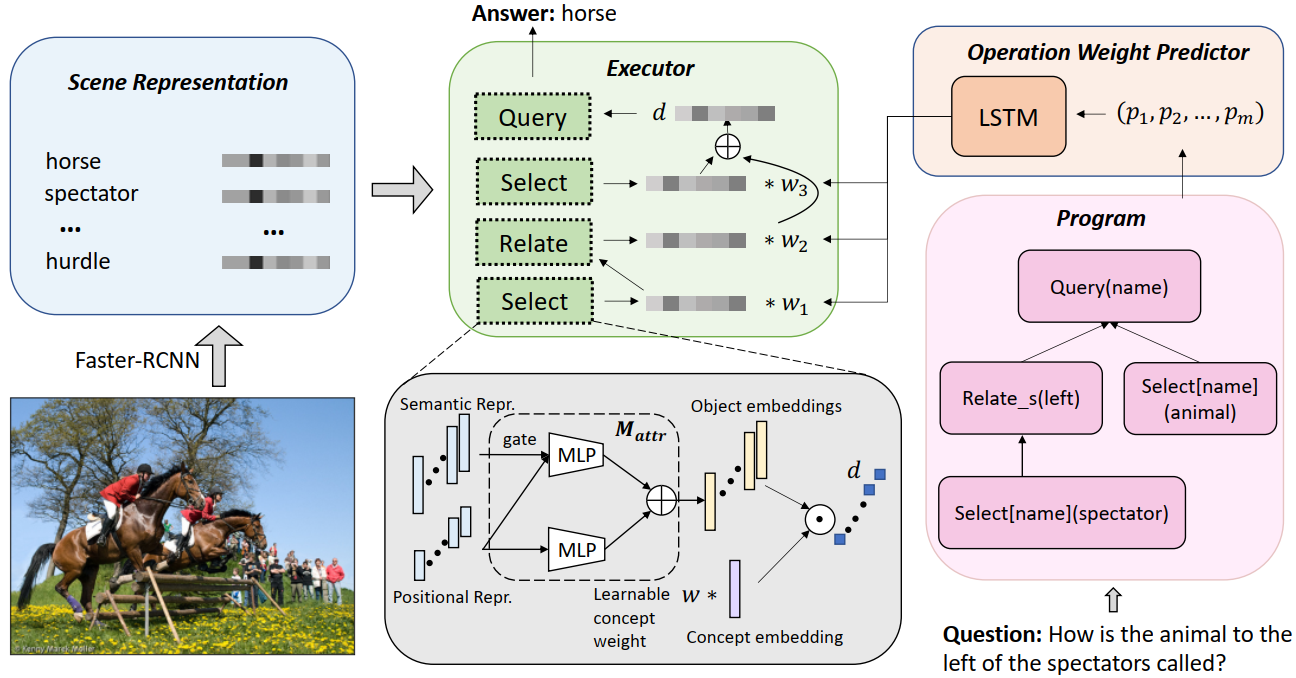
“Figure 3: Overview of our method. We first parse the image into a symbolic scene representation in the form of objects and attributes, then parse the question into a program. In each reasoning step, a reasoning module takes in the scene representation and the instruction from the program, and outputs a distribution over objects. The Operation Weight Predictor predicts a weight for each reasoning module, which will be used to merge module outputs based on the program dependency. The final distribution is fed into the output module to predict answers.”
Unfamiliar knowledge
Note: May include buzz word and potential literature.
Resources
Elementary drafts
Note: May contain Chinese. This section will disappear once all drafts are embellished.