Overview
Motivation
Most neural networks for computer vision are designed to infer using RGB images. However, these RGB images are commonly encoded in JPEG before saving to disk; decoding them imposes an unavoidable overhead for RGB networks.
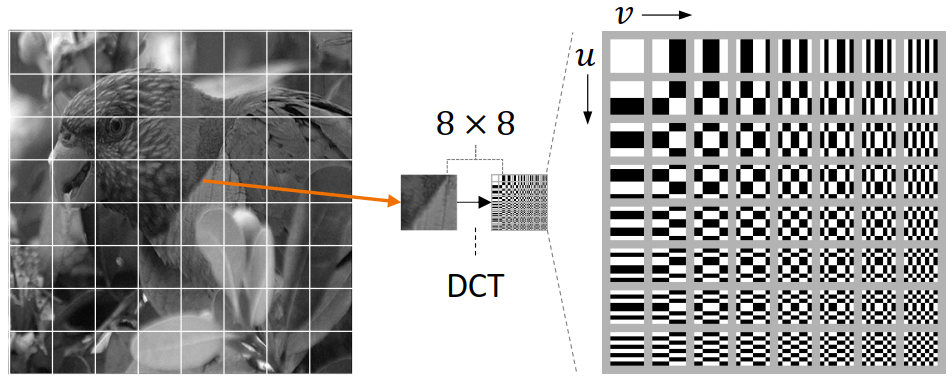
“Figure 2. Process of applying 8 × 8 DCT to the input image. The input image is sliced into 8 × 8 patches and the DCT is applied to each patch. The DCT bases are shown on the right.”
Resolution
This work focuses on training Vision Transformers directly from the encoded features of JPEG, which avoids most of the decoding overhead, accelerating data load. In addition, authors tackle data augmentation directly on these encoded features, which has not been explored in-depth for training in this setting.
Framework
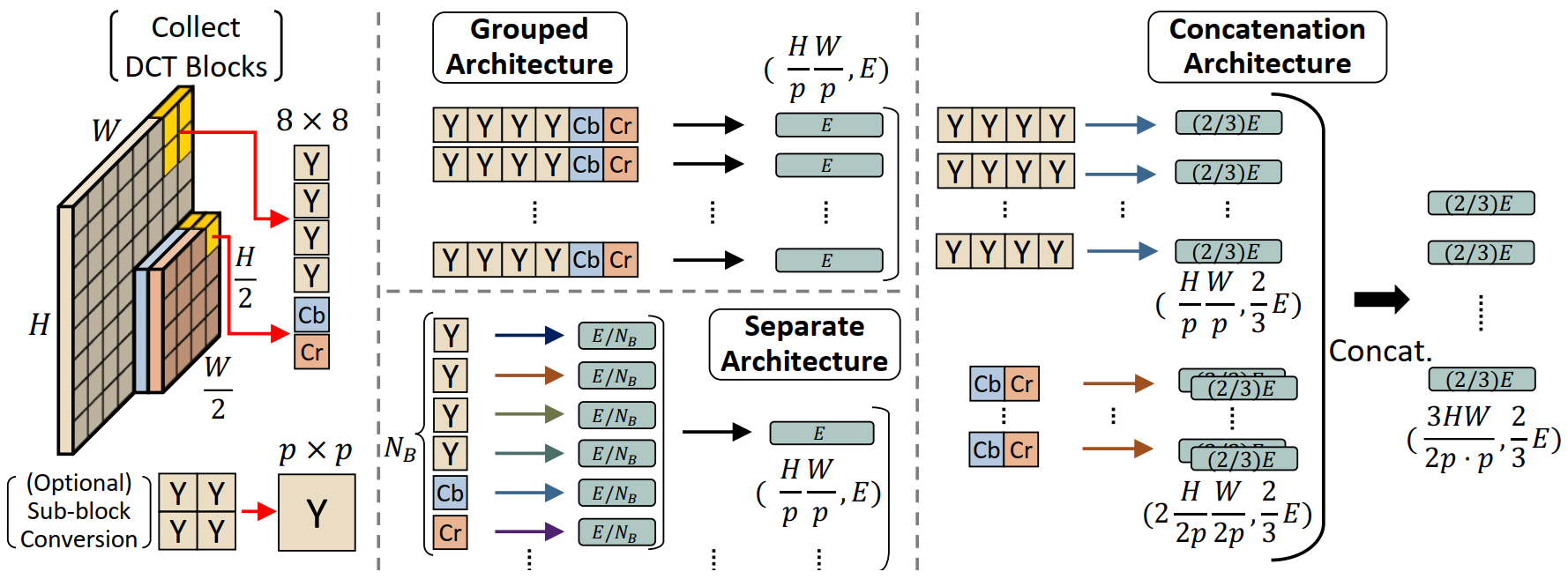
“Figure 4. Proposed model architectures. We first collect 8×8 DCT blocks until it matches the patch size. Then, these blocks are embedded through the different architectures. Grouped architecture groups all of the collected blocks and embeds them together. Separate architecture embeds each block separately and mixes it. Concatenation architecture embeds Y and U separately and concatenates them.”
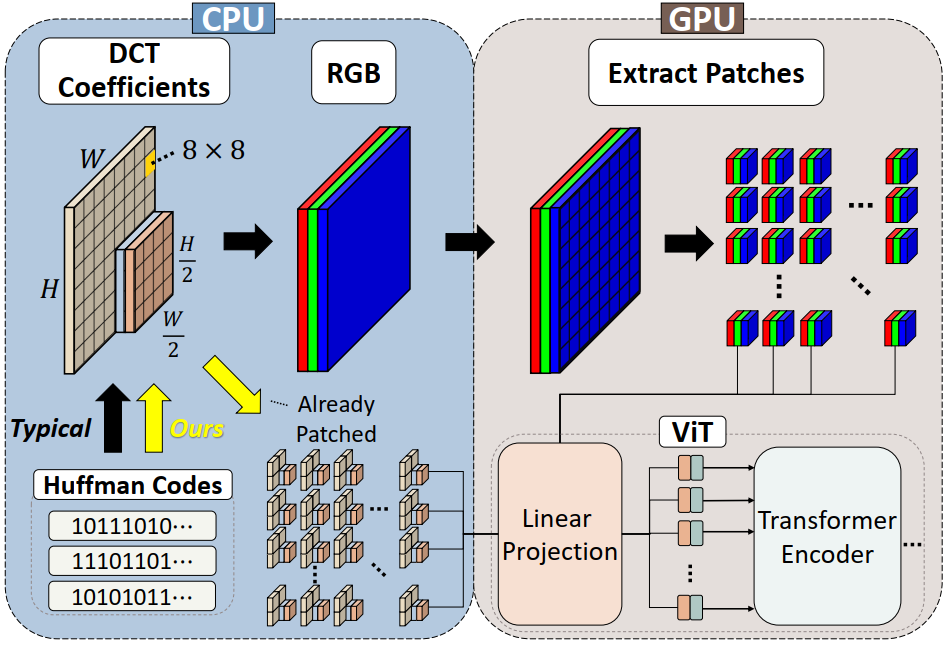
“Figure 1. Our proposed training process. The typical process requires full decoding as well as patch extraction to train. In contrast, our process does not since the DCT coefficients are already saved in block-wise fashion. As ViTs work on image patches, we can directly feed these coefficients to the network.”
Arguments
DCT inputs
Data is typically loaded by the CPU while the network runs on a GPU or other accelerator; more efficient data loading can thus reduce CPU bottlenecks and accelerate the entire pipeline.
Authors show that ViTs can be easily adapted to DCT inputs by modifying only the initial patch embedding layer and leaving the rest of the architecture unchanged.
Augmentation
Some standard augmentations such as image rotation and shearing are costly to implement in DCT, so authors also introduce several new augmentations which are natural for DCT.
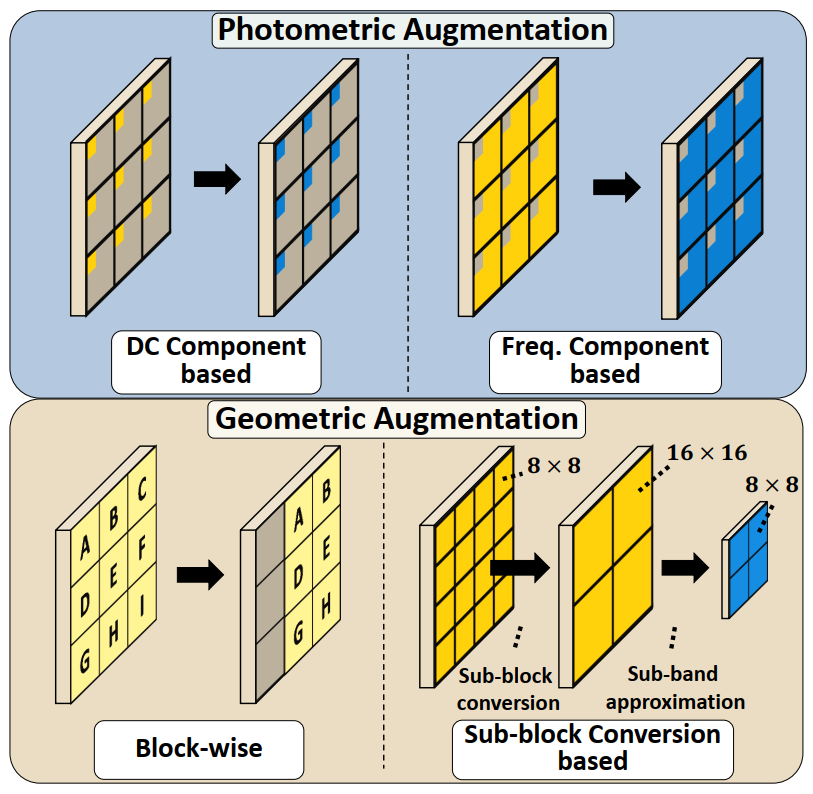
Figure 5. A visualization of different DCT augmentation types. Orange-colored coefficients are augmented and saved as bluecolored ones. The bottom two examples illustrate Translate and Resize augmentation.
Unfamiliar knowledge
Note: May include buzz word and potential literature.
JPEG files store image data using Huffman codes
discrete cosine transform (DCT)
luma data and chroma data
[Paper] Faster Neural Networks Straight from JPEG.
[Paper] Learning in the frequency domain.
[Paper] Randaugment: Practical automated data augmentation with a reduced search space.
video codecs
YCbCr color space
Run-length encoding(RLE)
Resources
Elementary drafts
Note: May contain Chinese. This section will disappear once all drafts are embellished.